
关于IGV记忆模块的一些近期工作与思考
高效而精确的记忆模块在IGV系统中至关重要,没有良好的记忆方案,IGV的长度将永远受限于存储和算力。
定义与研究现状#
在可交互视频生成(Interactive Video Generation,IGV)领域中,Memory模块负责确保生成内容在静态和动态方面的连贯性。具体来说,它包括两个部分:
- 静态记忆(Static Memory):保留场景级和对象级的信息,例如游戏地形、建筑结构、角色资产和对象表
- 动态记忆(Dynamic Memory):管理时间运动模式和行为序列,包括角色动画、车辆路径、粒子系统和动态环境元素(如天气变化)
现有工作主要依赖注意力机制中的交叉注意力来保持视频的前后一致性,但存在保持程度不佳和记忆时间不长的问题[1]。为此一些工作设计了新的记忆结构,使用高维潜空间或显式的三维空间表征(如GS,pointcloud),但这些模块还需要进一步适配完整的视频生成系统,训练这些记忆能力也需要更多优质数据集。
对记忆模块的讨论开始得较晚,在视频生成效果较好之后,才会考虑如何保持场景一致。早期工作直接依赖模型自身固有的记忆能力,未作深入探讨,此处不再赘述。以下为一些涉及记忆模块的代表性工作的发布时间:
- 利用模型自身交叉注意力
- 利用显示的3D建模作为记忆存储
- WonderWorld ↗, 2024-06
- Gen3C ↗, 2025-03
- Learning 3D Persistent Embodied World Models ↗, 2025-05
- Video World Models with Long-term Spatial Memory ↗, 2025-06
- VMem ↗, 2025-06
- WonderFree ↗, 2025-06
- 利用上下文的隐式记忆嵌入
- StreamingT2V: Consistent, Dynamic, and ExtendableLong Video Generation from Text ↗, 2024-03
- SlowFast-VGen ↗, 2024-10
- WORLDMEM: Long-term Consistent World Simulation with Memory ↗, 2025-04
- Long-Context State-Space Video World Models ↗, 2025-05
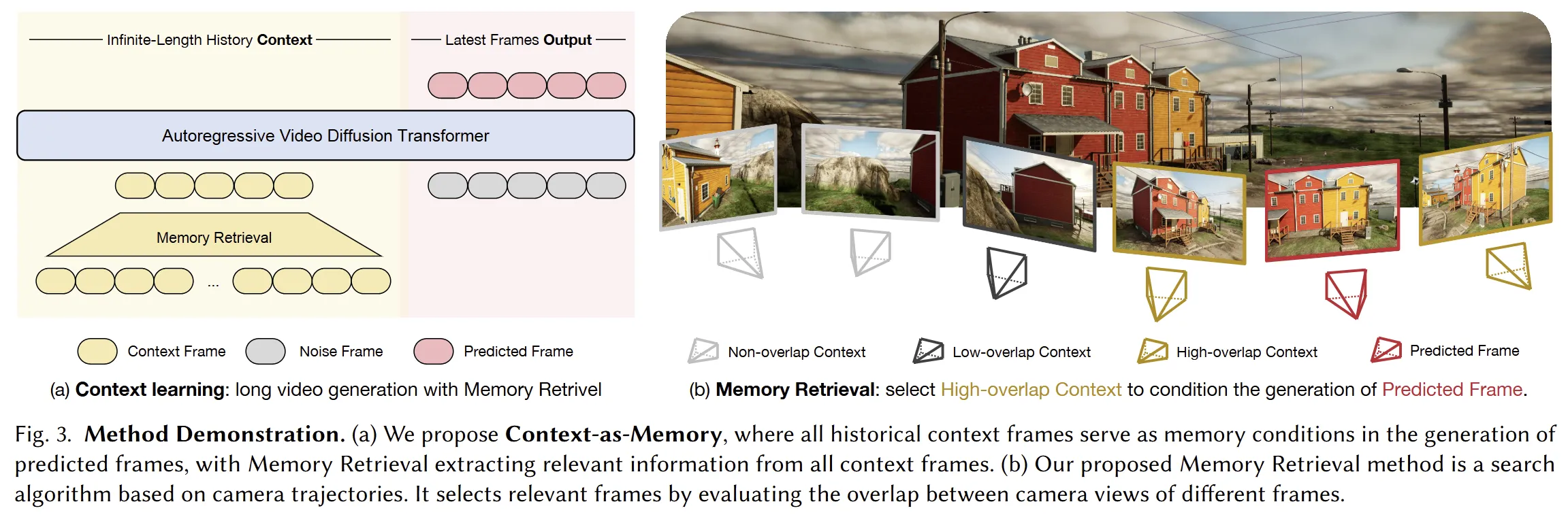
- Context as Memory ↗, 2025-06
- M3-Agent ↗, 2025-08
总的来讲,前沿的工作还是以滑动窗口为主,配合对长期记忆的存储、更新和抽取,而难点在于长上下文情景下如何高效地做长期记忆操作,如何对已有记忆进行筛选。对此,既有工作中有用到camera pose匹配(context as memory等)。采访中提到,Genie-3采用的是隐式策略。
本文将着重探讨采用显式(Explicit)与隐式(Implicit)方案的新一代记忆模块,均为一年以内的较新研究成果。
[1] A Survey of Interactive Generative Video ↗
基于三维重建的显式方案#
显式地表征三维场景,并在生成时用于参考,对较大物体的重建效果不错,且较容易落地;但是重建误差决定了该方案存在上限,例如VMem为了效率对细节丢失较多,深度估计也有固有误差,拓展难度高。
Video World Models with Long-term Spatial Memory#
三种记忆的融合:
- 长期空间记忆,即静态点云(static point cloud),经过TSDF滤波
- 短期记忆,即最近几帧
- 长期事件记忆,选择具有代表性的帧存储为historical reference,选择方法即帧间差距较大时触发
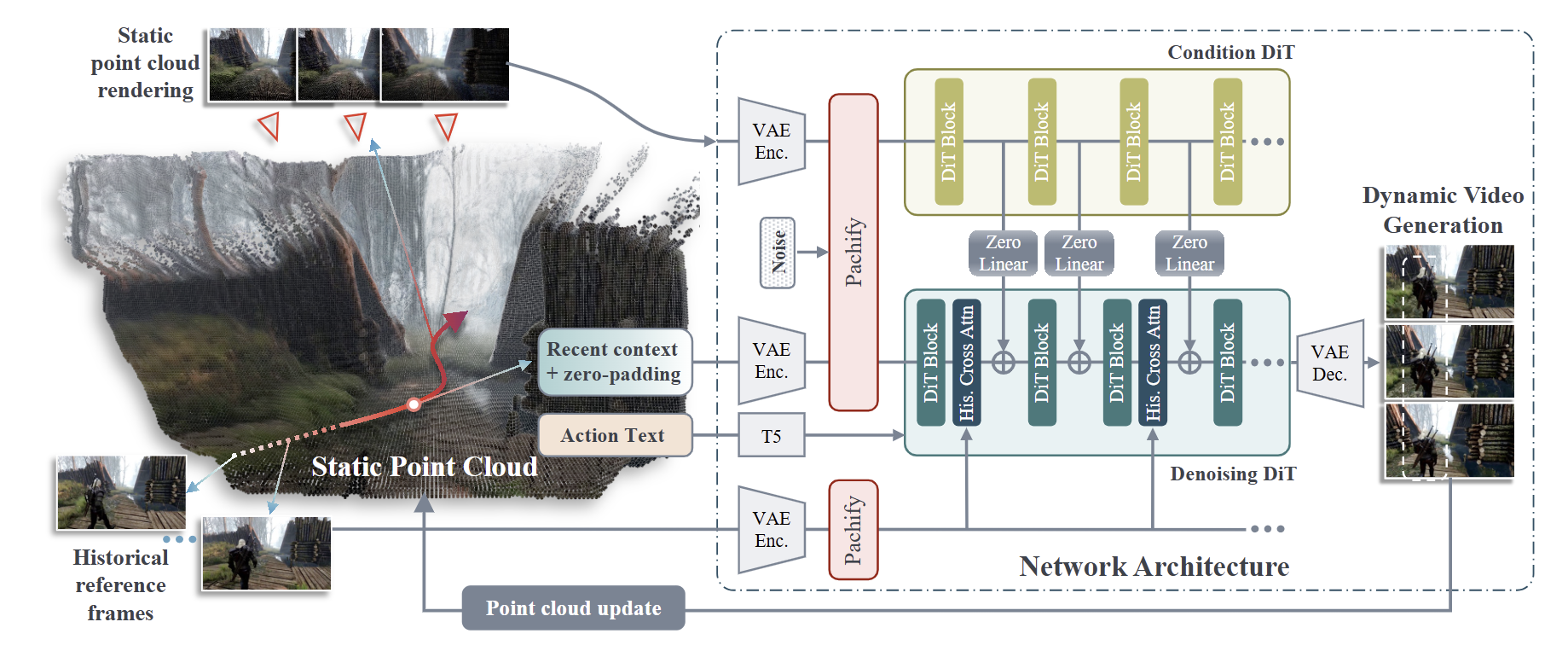
使用CUT3R生成点云,CogVideoX作为基座视频生成模型,TSDF将新点云与现有点云融合更新。利用3D点云使视频前后一致的设计参考了ControlNet。
VMem#
用Surfel(表面元素)作为更轻量的索引
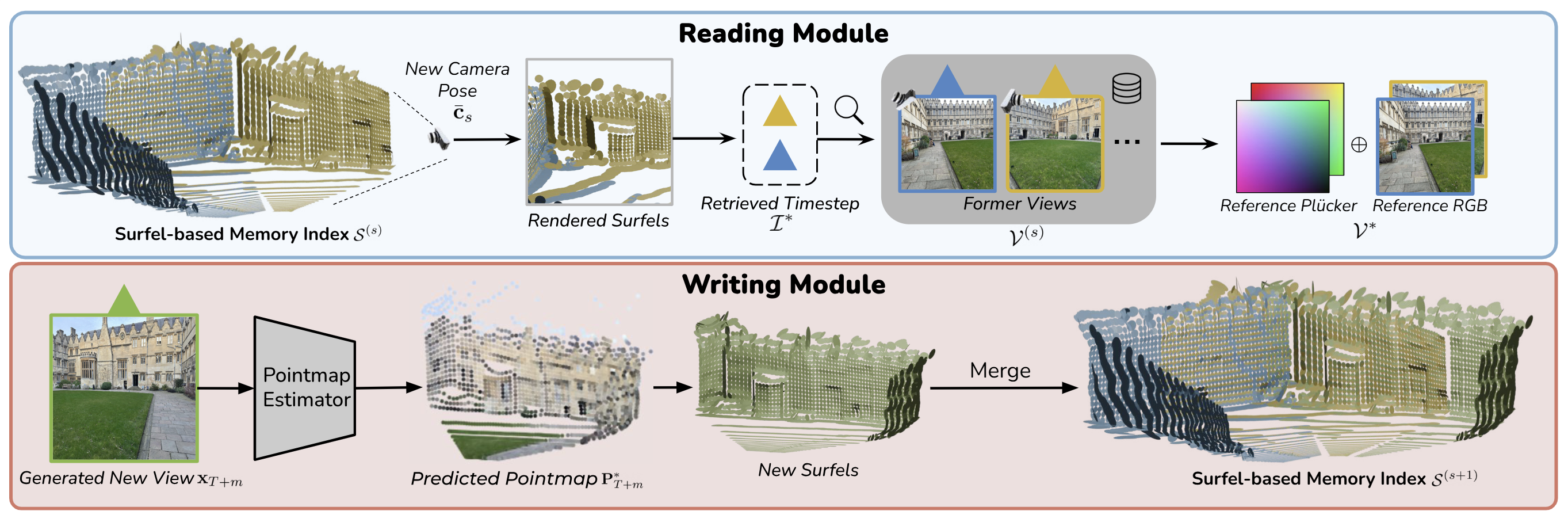
方法:https://v-mem.github.io/img/video-1min-encoded_720p.mp4 ↗ 很清晰的视频
Plücker是能表征图中任一点关于当时相机的位置的射线方程(包括相机起点),与拍到的内容无关
VMem在单图长程回访一致性、计算效率上占优;spatial memory在动态场景、动作一致性、文本-动作联合控制上更强,但依赖更重的点云融合管线,速度明显慢。
其他工作#
- Learning 3D Persistent Embodied World Models ↗ 用网格将整个空间分割,每次更新每块的内容,仅对小空间适用。用DINO-v2提取每帧的内容并用于更新,用深度图和camera pose计算图中内容的位置并更新对应区块
- WonderFree: Enhancing Novel View Quality and Cross-View Consistency for 3D Scene Exploration ↗ 基于3DGS生成粗糙世界后用两个模块精细化,但仅用于生成世界,并非实时探索的视频生成。基于Wonderworld,该系列工作还有wonderturbo(提高实时性,生成仅需0.72s)。
- GEN3C: 3D-Informed World-Consistent Video Generation with Precise Camera Control ↗ 用一个可实时更新的 3D 点云缓存当“外置记忆”,把已生成的场景几何和颜色都存进去。比较朴素的方法。
基于纯上下文的隐式方案#
没有固有误差,理论上限更高,但十分依赖精心设计的结构和训练,且显著data-driven,要求大量高质的数据用于训练。
SLOWFAST-VGEN#
核心创新为时间LoRA模块
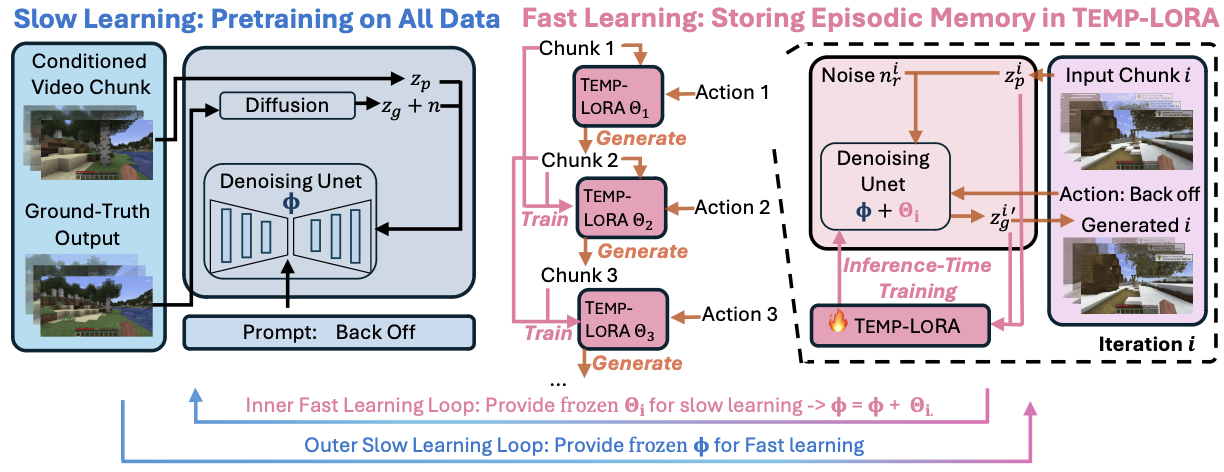
- 慢速训练即常规的后训练,基于预训练的 ModelScopeT2V 模型,通过掩码条件视频扩散来生成视频。可将输入视频块和动作描述作为条件,生成后续的视频块。 训练Unet:用三元组[输入,指令,加噪的输出]训练,学习去噪能力(找到那些噪声的)
- 快速训练的时间LoRA模块:在推理过程中训练,用当前视频片段和上一个片段和当中的指令训练,基于生成的视频和实际的差距训练小矩阵,叠加到慢速学习出来的矩阵中,继续下一步推理
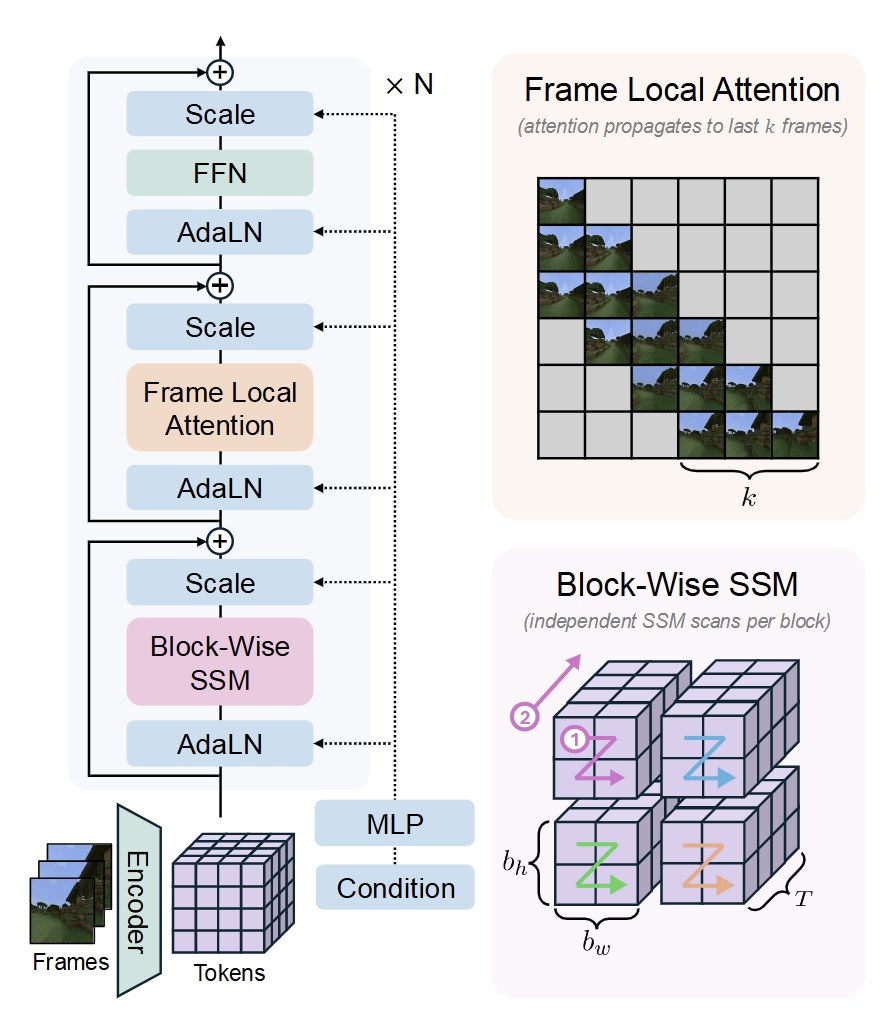
Long-Context State-Space Video World Models#
在时序维度引入Mamba,负责长程记忆的同时控制复杂度,加上最近几帧用来补充;训练时对前缀帧进行随机保留(不添加噪声的干净帧)
并没有用到具体的记忆模块,而是利用了Mamba的机制提高模型的长程记忆能力,只需维护常数内存,不会因为推理进行而内存爆炸;但是因为单帧计算量变大,所需时间长达200~400ms;推理长度不能超出训练长度,空间保真性也尚待提升。
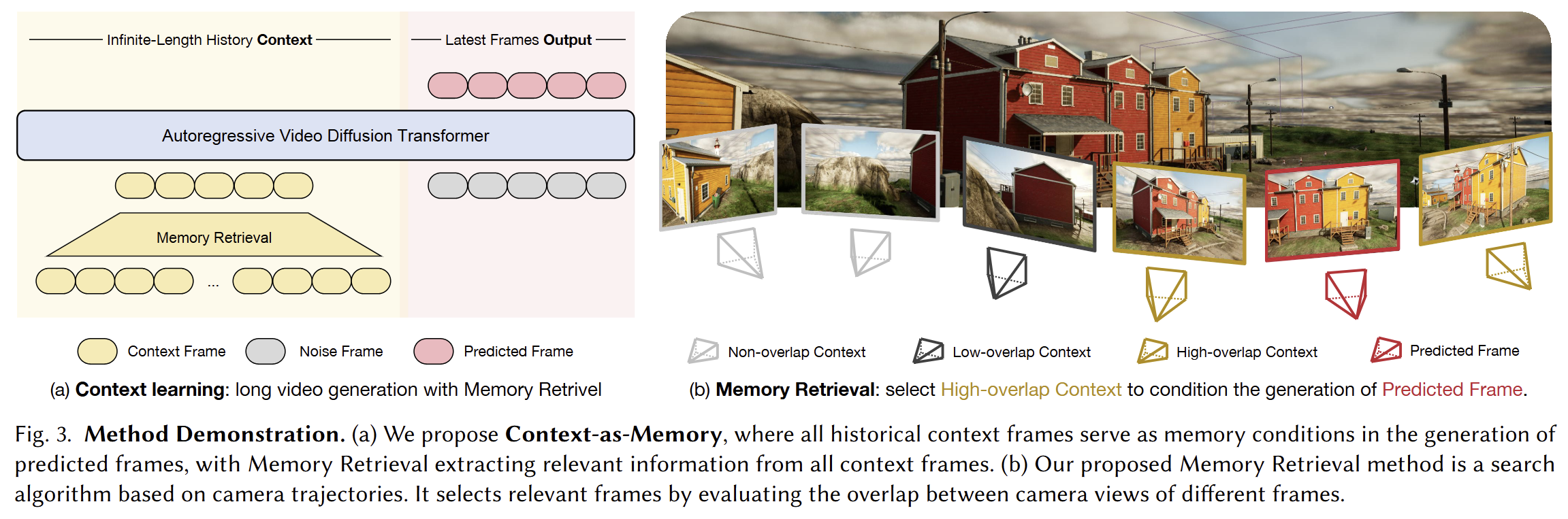
Context-as-Memory#
号称最接近Genie3的工作,核心是对相机位姿的存储和调用。
对每一次生成,进行如下操作:
- 遍历历史所有帧,计算与当前FOV的重叠度
- 去除时间冗余,连续多帧高重叠度的只保留一帧;对时空差距较大但重叠度仍较高的帧额外保留
- 筛选出一定数量的帧,与临近的几帧拼接后进行生成
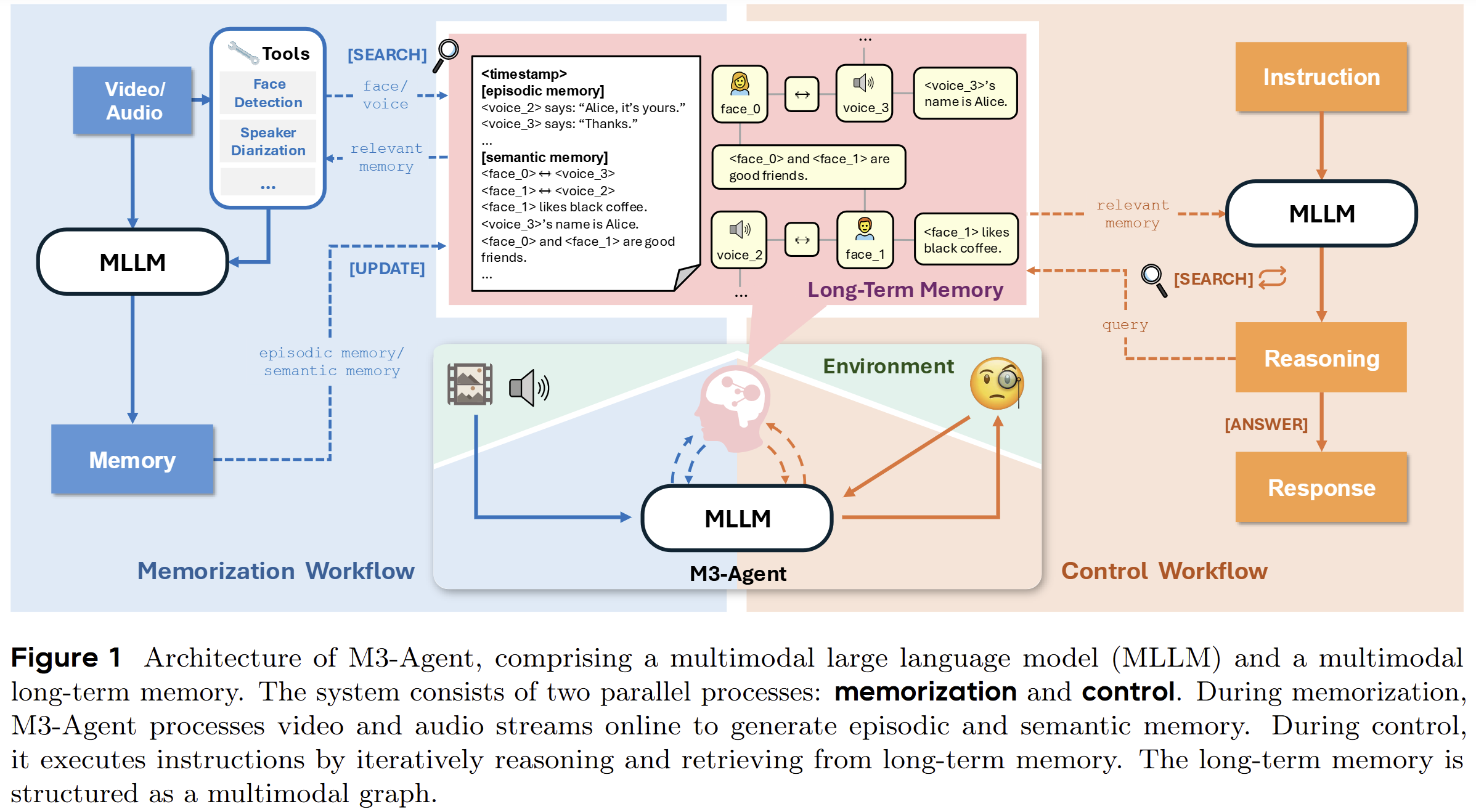
M3-Agent#
有多模态记忆系统的agent,不是一个直接用于视频生成的模型架构
- 有多模态的记忆,将一个实体的不同信息放在同一个槽中同维度存储,时序存储带有实体ID的记忆
- 检索时,基于时间范围和实体ID进行搜索
- 层级图,类似人类记忆的不同内容间的关系网络,在有新的事件/实体出现时立即更新
- 每一段时间进行记忆压缩,生成长期记忆,删除低置信度的关系线段
其他工作#
- StreamingT2V: Consistent, Dynamic, and ExtendableLong Video Generation from Text ↗ 持续用第一帧内容提醒模型;用了一个预训练的高分辨率短视频增强模型逐段增强
- WORLDMEM: Long-term Consistent World Simulation with Memory ↗ 和Context-as-Memory的方案类似,但把所有的关键帧都存储下来作为一个显式的库,而后者采用的其实是实时更新的最重要帧集合,worldmem的一致性更强,但是时间长后必然存在CPU/存储瓶颈,且频繁检索导致的延迟不可忽视
Discussion#
近期的工作大多在显式三维表征和隐式上下文建模之间徘徊。前者依赖点云、surfel 或体素等结构,能够提供明确的空间约束,但重建误差和更新效率始终是瓶颈;后者则完全交由模型内部机制维持一致性,避免显式误差,却需要更大规模的数据和更复杂的训练范式。值得注意的是,两类方法展现出一种逐渐融合的趋势,例如 context-as-memory 依靠相机位姿筛选历史帧,VMem 用轻量化的 surfel 作为索引。同时,研究者开始探索更接近人类认知的记忆机制,如层级抽象、语义压缩、多模态槽位存储,以缓解长时序生成中的存储和检索压力。
就目前的研究而言,Memory Module仍然是各个IGV System的痛点,Long-context Consistency还没有很完整的解决方案,尤其是能够结合动态、交互的记忆模块还很欠缺。到底是在效率、准确性和泛化能力之间找到合适的折中点,用算力或数据集弥补剩余空缺,还是能开创出全新的记忆模式?